![]()
Continuous Real-Time Signal Processing:
Jeffry Milrod,BittWare, Inc.December 18, 2002
One of the most daunting challenges facing designers of complex, real-time signal processing systems is choosing the most effective processor for a given task. Tradeoffs are difficult to define, much less evaluate, because the effectiveness of a processor is highly dependent on the application and involves all aspects of architecture and implementation.
When evaluating processors, simply relying on easy to digest benchmarks, sometimes known as bench-marketing, can be misleading as it tends to gloss over many of the subtle implementation issues that can cripple real-world performance. The other extreme is to implement the application (or a key subset) on different potential processors, and then evaluate the actual performance of each processor and/or implementation. This is obviously an extremely expensive and time-consuming approach, making it impractical for all but the most exorbitant evaluations. Effective tradeoffs must take into account system and implementation issues, yet still be reasonable in scope.
This article attempts to help with such tradeoffs and evaluations, particularly regarding continuous real-time signal processing applications as typified by the 1024-pt complex Fast Fourier Transform (cFFT). Specifically, we will evaluate the ‘highest’ performance processors that are being promoted for use in real-time signal processing systems by several COTS board vendors: Analog Devices’ TigerSHARC DSP (ADSP-TS101S); and Motorola’s PowerPC Family (MPC7410 & MPC7455) with the AltiVec vector processing core.
These processors represent radically different architectures and significantly different approaches to high-performance computing. The TigerSHARC represents a traditional approach to DSP with low-latencies, determinism, and DMA engines, and was developed to address embedded real-time applications such as radar, sonar, wireless communications, and image processing. Conversely, the PowerPC is a RISC processor that was developed for Apple Computer’s highest performance G4 workstations but has found great success in some embedded signal processing applications due to its tremendous clock rates and powerful AltiVec vector processing engine.
Clearly, the G4 PowerPC (74xx) with AltiVec core has better core clock rates and raw-performance benchmarks. As shown in Table 1, the core clock rate of the PowerPC is as much as 3.3 times that of the current TigerSHARC (although faster versions of the TigerSHARC have been announced, and will be released shortly). The AltiVec core performs a single instruction each cycle on a 128-bit vector comprised of four separate 32-bit data elements, this is known as a SIM-D (Single-Instruction, Multiple-Data) architecture. Peak processing is achieved when performing a Multiply-ACcumulate (MAC) instruction on the vector, yielding eight floating-point operations per cycle for a peak raw-performance of 8,000 MFLOPS (Million FLoating-point OPerations per Sec) for the 1 GHz MPC7455. Alternatively, the AltiVec can execute eight integer, or fixed-point, operations per cycle, resulting in 8,000 MOPS (Million OPerations per Second) peak integer performance.
|
|
TigerSHARC |
PowerPC |
|
|
Parameter |
ADSP-TS101S |
MPC7410 |
MPC7455 |
|
Core Clock |
300 MHz |
500 MHz |
1,000 MHz |
|
Peak Floating-Point Performance |
1,800 MFLOPS |
4,000 MFLOPS |
8,000 MFLOPS |
|
Peak 16-bit Integer Performance |
7,200 MOPS |
4,000 MOPS |
8,000 MOPS |
|
Memory Bus Size/Speed |
64-bit/100 MHz |
64-bit/125 MHz |
64-bit/133 MHz |
|
External Link Ports |
4@250 MB/sec |
not applicable |
not applicable |
|
I/O Bandwidth (inc. memory) |
1,800 MB/sec |
1,000 MB/sec |
1,064 MB/sec |
|
Bandwidth-to-Processing Ratio |
1.00 B/FLOP |
0.25 B/FLOP |
0.13 B/FLOP |
|
On-Chip RAM |
786 KB |
64 K |
320 KB |
|
External Cache |
not applicable |
L2: 1 or 2 MB |
L3: 1 or 2 MB |
|
Power Consumption (typ.) |
1.9 W |
5.5 W |
21.3 W |
|
MFLOPS/Watt |
947 MFLOPS/W |
727 MFLOPS/W |
376 MFLOPS/W |
Table 1: Raw Performance Metrics & Processor Overview
Conversely, the TigerSHARC has two independent 32-bit processing cores, or a MIM-D (Multiple-Instruction Multiple-Data) architecture. Each computational unit can perform a multiply, as well as a simultaneous sum and difference in a single cycle, resulting in six FLOP per cycle or 1,800 MFLOPS peak performance for the 300 MHz ADSP-TS101S. When performing 16-bit integer functions, the TigerSHARC can utilizes its SuperScalar architecture to split the two independent 32-bit computational units in to two separate 16-bit SIMD units that can each operate on 2 data elements for a total of up to twelve operations per cycle. In addition, the TigerSHARC has another two dedicated 16-bit integer engines that add twelve more operations per cycle, for a total of twenty-four integer operations per cycle, or 7,200 MOPS.
Since many signal processing applications, if not most, are limited by data flow rather than processing, it is important to understand the processor I/O capabilities and how well it feeds the processor core. One measure of this relationship is the I/O Bandwidth-to-Processing Ratio (BPR), which is simply the peak I/O bandwidth (in MB/sec) of a processor divided by it’s peak processing power (in MFLOPS). A BPR of 1 B/FLOP is indicative of a well-balanced, continuous signal processing architecture, and means that a processor can move 1 Byte of data on/off-chip for every floating point operation the core can perform. A processor with a BPR significantly higher or lower than 1 B/FLOP indicates an architecture that is better suited to data movement or back-end data processing than to continuous signal processing.
Figure 1 shows a generic block diagram of a PowerPC processing node. This processor provides support for cache-coherent shared-memory architecture with high cross-sectional bandwidths; however, all processor I/O must flow through the 64-bit, 125 MHz (133 MHz for MPC7455) system bus between the MPC and the Controller/bridge chip. As shown in Table 1, the peak I/O bandwidth into any one node is 1,000 MB/s for the MPC7410, and 1,064 MB/s for the MPC7544.
Because the Altivec is so powerful however, this seemly high bandwidth is not always enough to keep up with the core. Potentially, the MPC7455 can perform 8,000 MFLOPS while it can only move 1,064 MB/sec of data. As shown in Table 1, this yields a BPR of only 0.13 B/FLOP, indicating that this architecture has unbalanced I/O and processing power. Therefore, the PowerPC is efficient for block processing (i.e. high computations with relatively low data flow), but it is inefficient for continuous signal processing which is typified by relatively low computations with continuous, high data flow.
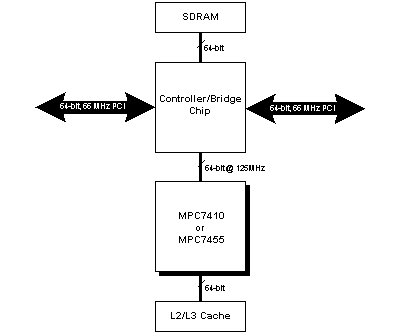
Figure 1: Generic PowerPC Processor System Node Block Diagram
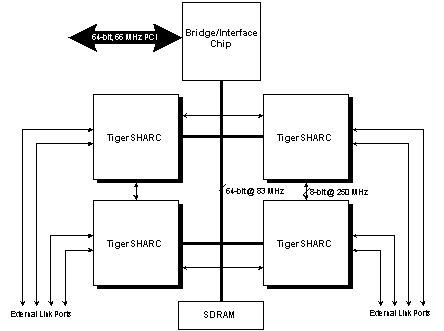
Figure 2: Generic TigerSHARC Processor System Cluster Block Diagram
The TigerSHARC is designed for multi-processing and provides for a shared system bus (64-bits @ 100MHz) as well as four link ports (8 bits @ 250 MHz each) for I/O and interprocessor data flow. Data can be moved over the cluster bus at up to 800 MB/sec. Additionally, data can be transferred via the link ports at 250 MB/sec each, providing an aggregate I/O bandwidth of up to 1,800 MB/s per TigerSHARC. As shown in Table 1, the TigerSHARC has a BPR of 1.0 B/FLOP, indicating a balanced architecture well optimized for continuous signal processing.
The 1024-point complex Fast Fourier Transform (cFFT) is the most widely used benchmark to evaluate signal processing performance, and is shown in Table 2. This is due to several reasons. First, it is unambiguous and easily quantified; secondly, it is almost certainly the most widely used signal processing function and is used in most applications. Finally, it evaluates both the processing and data handling capabilities of the processor.
Note that the PowerPC has a significantly better 1024-pt cFFT benchmark due to its raw speed and performance. However the TigerSHARC, tailored for DSP, is more efficient at implementing this quintessential signal processing algorithm. This is due to the chip’s ability to move data extremely well, its balance, and its ability to perform the ‘butterfly’ computation (multiply, sum, and difference) in a single cycle. The AltiVec core is 3.3 times faster than the TigerSHARC’s and achieves potential processing rates that are 4.4 times faster, yet it performs a 1024-pt cFFT only 2.5 times faster. While the TigerSHARC can perform the function in 9,750 cycles, the PowerPC requires around 13,000 cycles. Therefore, the TigerSHARC is 33% more efficient processing a 1024-pt cFFT than the PowerPC; in other words, a TigerSHARC would outperform a PowerPC by 33% if running at the same clock rate. As TigerSHARCs continue achieve faster clock rates, or if more can be brought to bear on a given problem (due to less real estate, power, cost, etc…), it will clearly out-perform the AltiVec cycle per cycle when it comes to FFT oriented signal processing applications.
|
|
TigerSHARC |
PowerPC |
|
|
Parameter |
ADSP-TS101S |
MPC7410 |
MPC7455 |
|
Core Clock |
300 MHz |
500 MHz |
1,000 MHz |
|
1024-pt cFFT Benchmark |
33 msec |
22 msec |
13 msec (est.) |
|
Approx. Cycles for 1024-pt cFFT |
9,750 cycles |
11,000 cycles |
13,000 cycles |
|
Continuous 1024pt cFFTs/chip |
30,769 per sec |
26,053 per sec |
64,941* per sec |
* Assumes 100% of I/O bandwidth is used for continuous cFFTs, and neglects cache & data movement overhead – real-world performance could be much less.
Table 2: 32-bit Floating Point, 1024-pt cFFT Performance Metrics
We’ve evaluated raw processing power, I/O bandwidth, and even algorithmic performance but, unfortunately, none of these evaluations truly reflect real-world applications; real applications require the complex interaction of all of these things. Data must be moved in, processed, and moved out – hopefully, all simultaneously. One easily grasped real-world example is the continuous 1024-pt cFFT, in which the processor computes as many discrete 1024-pt cFFTs per second as it can. While convenient, this example is not at all contrived – continuous cFFTs are frequently done for spectral analysis, pulse compression, frequency-domain filtering, and many other real-world applications. One is tempted to simply invert the well-known 1024-pt cFFT benchmark, but as we will see, that results in bench-marketing if the processor is I/O limited.
Each 1024-pt cFFT requires 8 KB data in (1024 samples x 2 samples/IQpair x 4 Bytes/sample) and 8KB data out, for a total of 16 KB (16,384 Bytes) of data flow. By comparing the inverse of the 1024-pt cFFT benchmark times 16 KB per 1024-pt cFFT with the I/O bandwidth of a processor, we can determine whether the processor will be limited by bandwidth or processing.
In the case of the TigerSHARC, the inverse of the benchmark, found in Table 2, would indicate that it could perform 30,769 1024-pt cFFTs per second. Since the TigerSHARC can move all the required data in background, this performance would require 504 MB/sec of data flow (30,769/sec x 16KB), which is easily sustainable by the I/O bandwidth of the processor. Therefore, the TigerSHARC is processor limited in this application and, as shown in Table 2, the inverse of the benchmark is correct.
For the MPC7410, the 1024-pt cFFT benchmark is misleading, since it can not move data and process at the same time. In addition to the processing time, the 8KB of input data must be moved into cache, and the 8KB of output data must then be moved out. This data movement adds 16.4 msec to the processing time, for a total time of 38.4 msec to implement a 1024-pt cFFT. Since the data movement is now explicitly accounted for, this application is now processor limited by definition and can sustain the inverse of the benchmark including data movement (i.e. 1/38.4 msec), as is shown in Table 2.
This is not the case, however, for the MPC7455. The inverse of its benchmark would indicate that the core could process 76,923 1024-pt cFFTs per second - requiring 1,260 MB/sec of data flow. Although this PowerPC can move data while it’s processing, it can only achieve a peak bandwidth of 1,064 MB/sec (as shown in Table 1). Therefore, it is bandwidth limited in this application. Assuming that it can continuously sustain the peak I/O bandwidth (cache management and controller bottleneck issues may significantly reduce this number, but are beyond the scope of this article), the MPC7455 can perform only 64,941 1024-pt cFFTs per second (1,064MB/sec divided by 16KB per 1024-pt cFFT) – significantly less than indicated by the inverse of the benchmark.
As previously mentioned, multiprocessor COTS boards are readily available for all of the processors discussed in either (or both) cPCI and VME formats. However, the above evaluations can change dramatically when the realities of board-level implementations are considered.
Since the MPC7455 is already bandwidth limited, any additional I/O limitation caused by board architecture will further degrade the continuous cFFT performance of the processor. Ignoring the backplane for data flow, the current best-case I/O available for PowerPC boards is two 64-bit/66Mhz PMCs. These dual PMCs can peak at 528 MB/sec transfer rates for a total of 1,056 MB/sec. This is already less than the MPC7455’s peak I/O bandwidth of 1,064 MB/sec, and in reality it's virtually impossible for the PMCs to continuously sustain that level of throughput. Even still, assuming a sustained I/O bandwidth of 1,056 MB/sec, a PowerPC board will be limited to 64,453 (1,056 MB/sec divided by 16 KB) sustained 1024-pt cFFTs per second per board - independent of number or speed of the PowerPCs.
Conversely, the TigerSHARC has scalable I/O via its link ports. Figure 2 shows a generic block diagram of a typical quad TigerSHARC processing cluster. In this example, each processor must share the cluster bus bandwidth and uses two link ports per processor for interprocessor data flow, with the other two link ports per TigerSHARC being used for I/O. This reduces the aggregate I/O bandwidth per processor to only 700 MB/sec (2 x 250 MB/sec for the link ports plus ¼ x 800 MB/sec of the shared cluster bus). Recall, however, that the TigerSHARC needs 504 MB/sec to feed each processor at the maximum continuous cFFT rate. While this rate is within the limits of the TigerSHARC, it is impractical for the continuous I/O to be split across link ports and the shared cluster bus. In practice, the maximum I/O data rate for continuous cFFTs is the 500MHz provided by the two link ports per TigerSHARC; this slight bandwidth limit reduces the continuous 1024-pt cFFT performance to 30,517 per TigerSHARC. Due to the low power, small size, and functional integration of the TigerSHARC, dual cluster boards (i.e. eight TigerSHARCs) are readily available in 6U formats. Therefore, as shown in Table 3, an octal TigerSHARC can sustain 244,135 continuous 1024-pt cFFTs per sec, or almost four times as many as an ideal PowerPC board can!
|
|
TigerSHARC |
PowerPC |
|
|
Parameter |
ADSP-TS101S |
MPC7410 |
MPC7455 |
|
Core Clock |
300 MHz |
500 MHz |
1,000 MHz |
|
Typical # Processors/Board |
8 |
4 |
2 |
|
FLOPS/Board |
14.4 GFLOPS |
16 GFLOPS |
16 GFLOPS |
|
Typical Off-Board I/O |
2 PMCs; 16 Links |
2 PMCs |
2 PMCs |
|
Off-Board I/O(not inc. backplane) |
5,056 MB/sec |
1,056 MB/sec |
1,056 MB/sec |
|
Power Consumption (approx.) |
25 W |
40 W |
60 W |
|
MFLOPS/Watt |
576 MFLOPS/W |
400 MFLOPS/W |
267 MFLOPS/W |
|
Continuous 1024pt cFFTs/Board |
244,135 per sec |
64,453* per sec |
64,453* per sec |
|
Continuous 1024pt cFFTs/Watt |
9765 cFFTs/W |
1611* cFFTs/W |
1074* cFFTs/W |
* Assumes 100% of peak PMC I/O used for cFFT data flow
Table 3: Board-level Performance Metrics
As surprising as these numbers for COTS board implementations may be, we have shown that they are not bench-marketing nor specsmanship, but are actually representative of real-world performance for continuous real-time signal processing applications. While the analysis of a myriad of other potentially important parameters for application tradeoffs (such as interrupts, development environments, DMAs, memory utilization, cache management, power, etc…) are beyond the scope of this article, the relevance of this continuous cFFT evaluation is clear.
If the application requires a lot of number crunching with little data movement, typical of so-called back-end data processing, then the PowerPC’s higher clock rate and more powerful core will be probably be more effective. For continuous real-time signal processing such as imaging, radar, sonar, sigint, and other applications that require high data flow or throughput, however, the TigerSHARC can dramatically outperform the PowerPC and is probably the preferred choice.
![]()